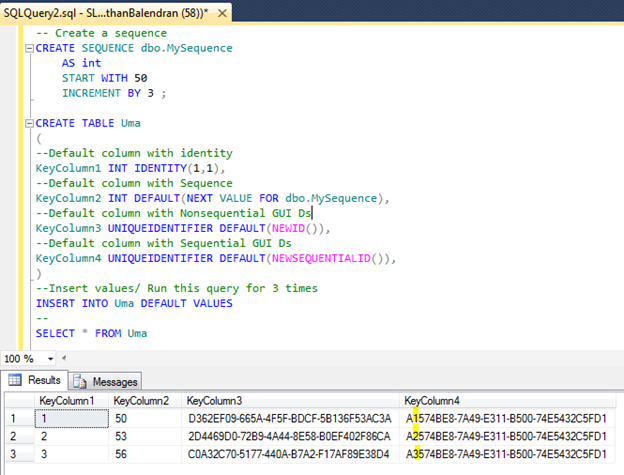
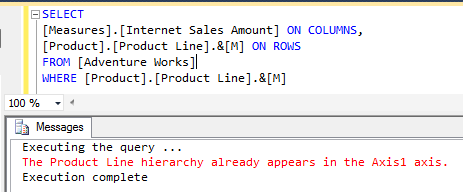
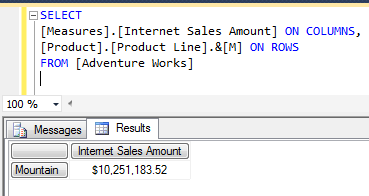
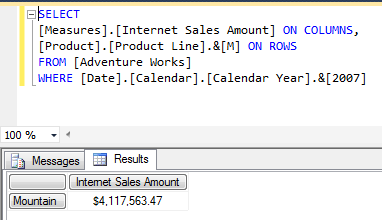
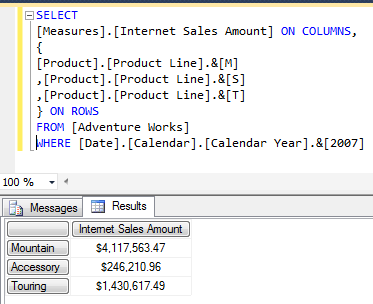
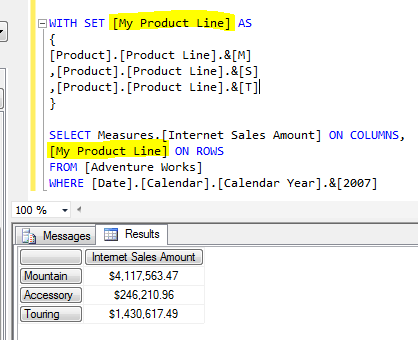
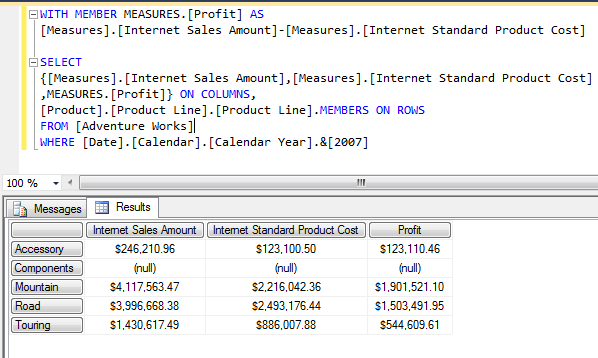
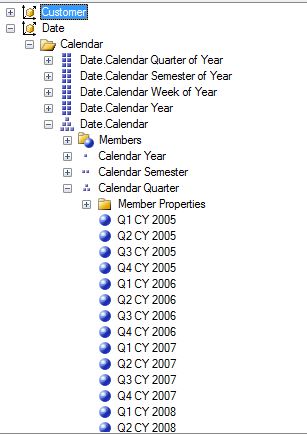
The typical options people use to generate key columns are:
- The identity column property A property that automatically generates keys in an attribute of a numeric type with a scale of 0; namely, any integer type (TINYINT, SMALLINT, INT, BIGINT) or NUMERIC/DECIMAL with a scale of 0.
- The sequence object An independent object in the database from which you can obtain new sequence values. Like identity, it supports any numeric type with a scale of 0. Unlike identity, it’s not tied to a particular column; instead, as mentioned, it is an independent object in the database. You can also request a new value from a sequence object before using it.
- Nonsequential GUI Ds You can generate nonsequential global unique identifiers to be stored in an attribute of a UNIQUEIDENTIFIER type. You can use the T-SQL function NEWID to generate a new GUID, possibly invoking it with a default expression attached to the column. You can also generate one from anywhere—for example, the client by using an application programming interface (API) that generates a new GUID. The GUIDs are guaranteed to be unique across space and time.
- Sequential GUI Ds You can generate sequential GUIDs within the machine by using the T-SQL function NEWSEQUENTIALID.
- Custom solutions If you do not want to use the built-in tools that SQL Server provides to generate keys, you need to develop your own custom solution. The data type for the key then depends on your solution.