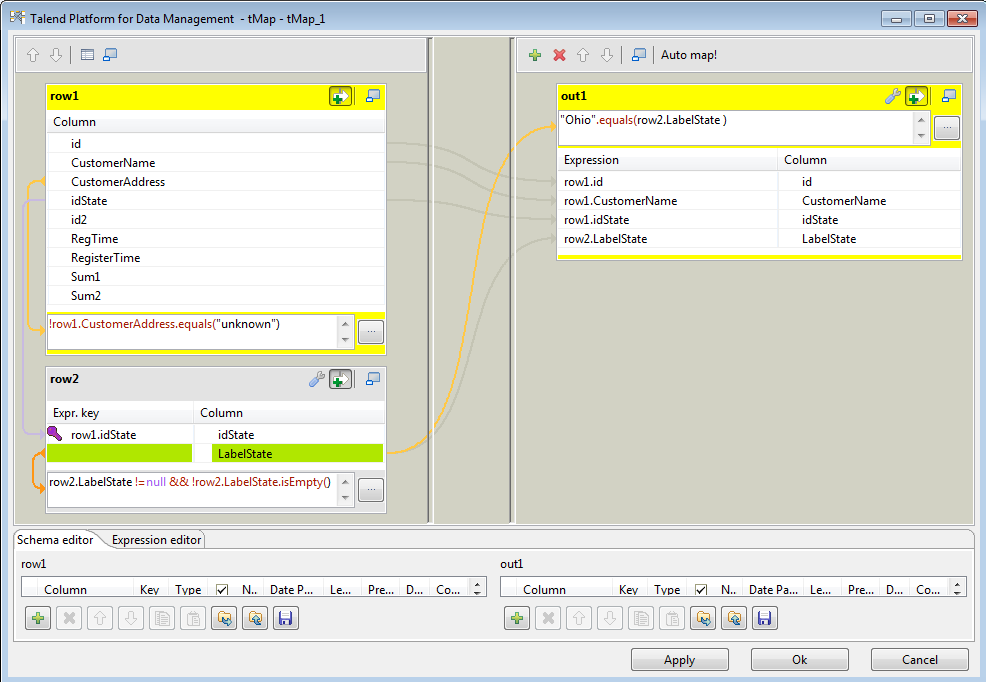
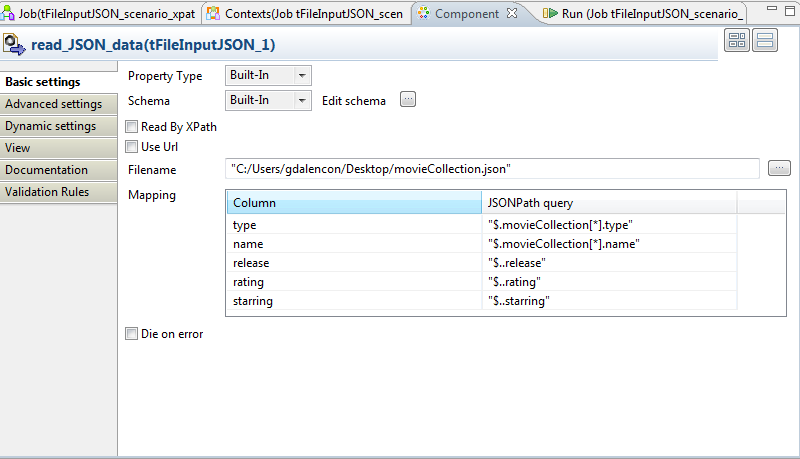
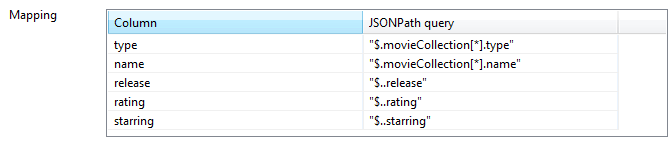
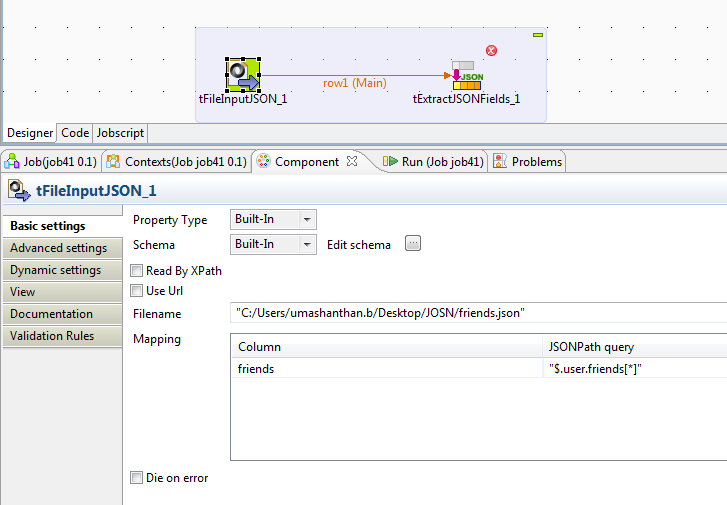
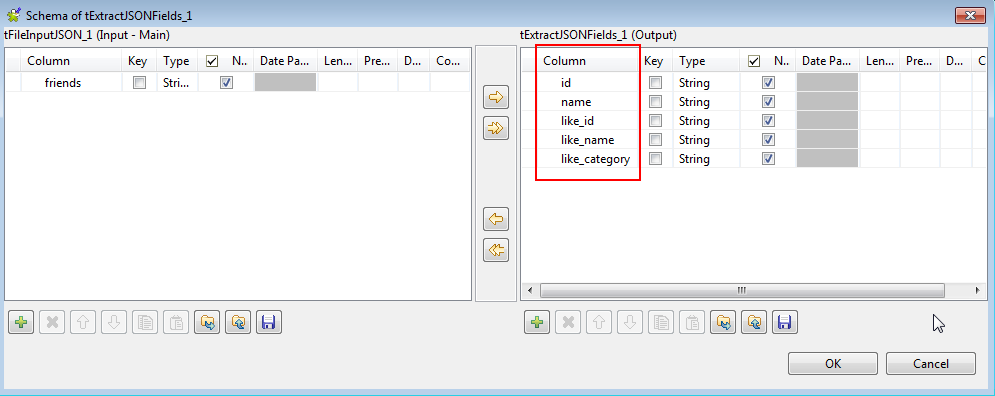
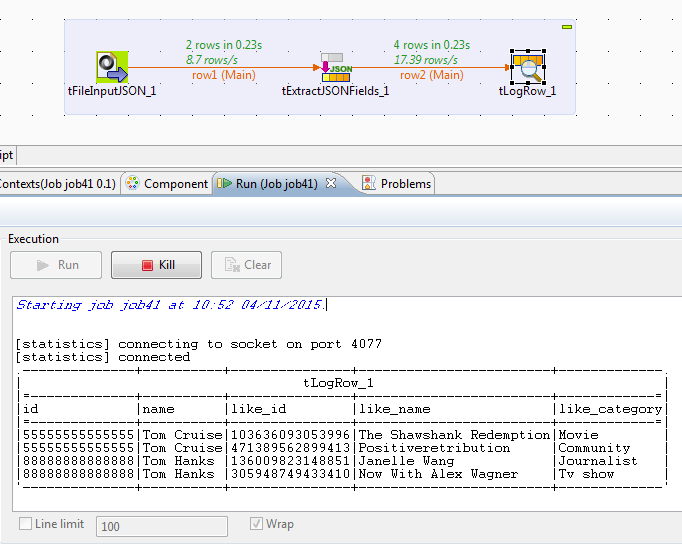
This post contains basic information about Hadoop and it's function. This content and images are collection of many already available posts. You can simply understand Hadoop terms by comparing Hadoop and Google terms. Because Hadoop is inspired by the Google techniques.
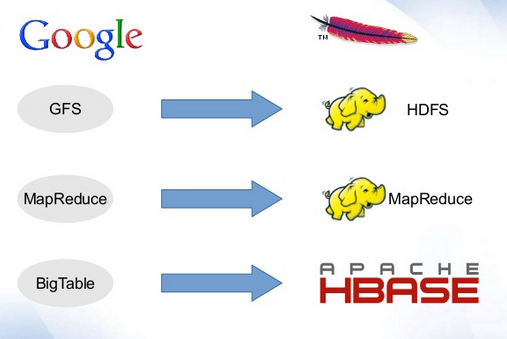
What is HDFS and why it is special?
The Hadoop Distributed File System (HDFS) is designed to reliably store very large files across machines in a large cluster. The HDFS is the primary storage system used by Hadoop application. In initially Yahoo was enhanced the GFS and released as HDFS.
Traditional file system block size is 4KB, but HDFS file block size is 64MB default, this can be increased up to 128MB. There are many other advantages HDFS file system over traditional file system. Note that this HDFS file system only useful when we handle with large size file.
First advantage is, Free space can be used to store other data, for example if you want to store 2KB file, it store in a block which is 4KB, inside this blog 2KB space is free, however this space cannot be used by other purposes by traditional file system, but HDFS file system is support to use this free space within a blog. For example if 30 MB File stored in a blog then excess 34MB Space will be used for other data storing.
Second important advantage is, less space for metadata when storing large file. Big blog size 64Mb reduce overhead for Name node, metadata less, less storage for name node. In traditional file system data split into so many 4KB chunks and need more space to store metadata of these chunks. More space is required to store metadata as well as file retrieval also will take more time. For example, if you need to store the 1GB File, only just 16 block are required (1024/64) in HDFS system for the block size 64MB, but in traditional file system 262144 (1024*1024/4) blocks are required.
Third advantage is provides reliability through replication. Each block is replicated across several Data Notes. By default HDFS set for 3 replication. If you store 64MB file, this will be store in three Nodes same file in a Block in the cluster system. If one data node down, no worries replicate data there, but if name node down no way. This is called single point of fail over.
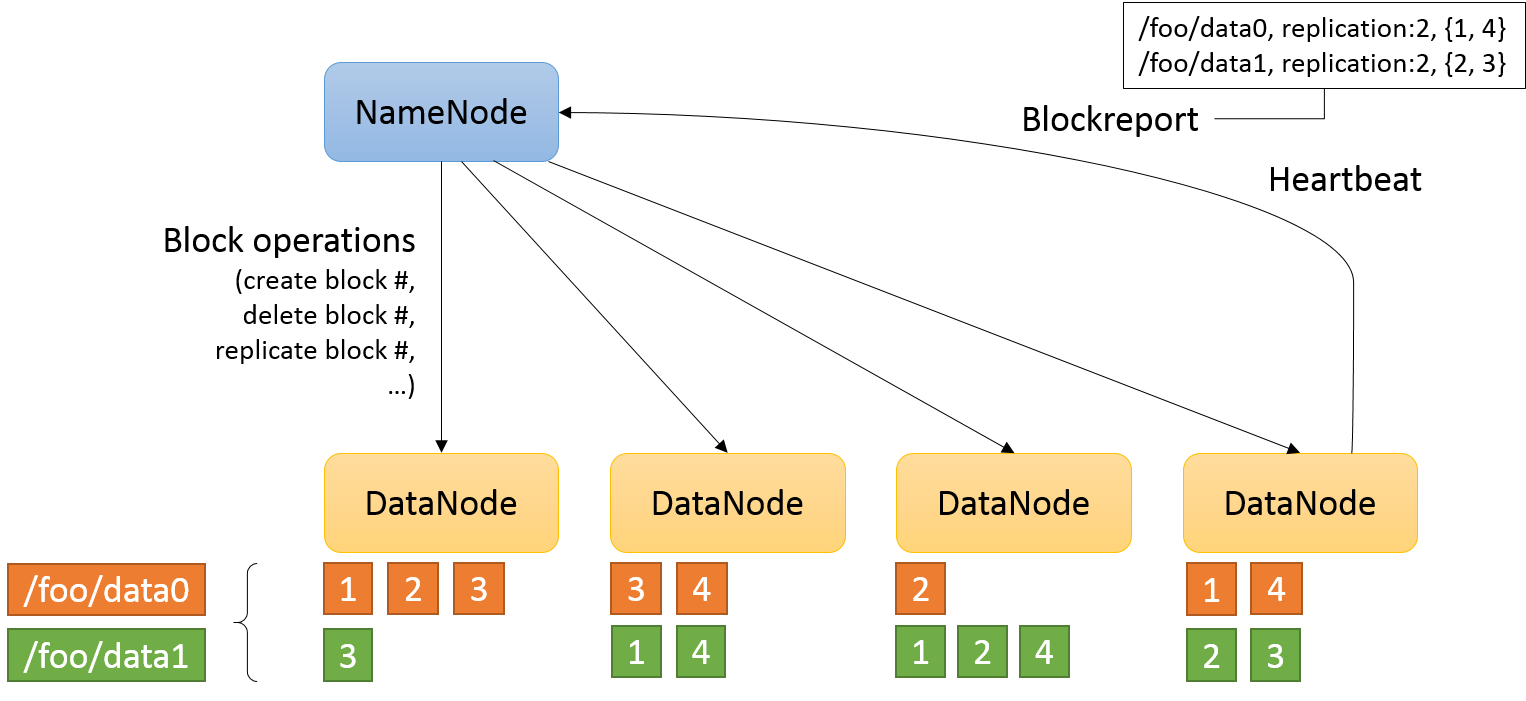
How HDFS system functioning
HDFS has five main services
- Name node
- Secondary Name mode
- Job Tracker
- Data node
- Task Tracker
First 3 are master service and last 2 are slave services. In this system Name note talk to Data note and Job tracker talk to Task tracker.


Actual data store in Data notes and Name note used to store Meta data
Actual data store in Data notes and Name note used to store Meta data
Secondary Name node is used in failure of main Name node


Let’s see with the example, how this system is functioning. In 200MB file needs to store in 64KB block size, in this file is chunked as 4 small file, which would fit to HDFS block size. Assume that those 4 files are a.txt (64MB), b.txt (64MB), c.txt (64MB) and d.txt (8MB).

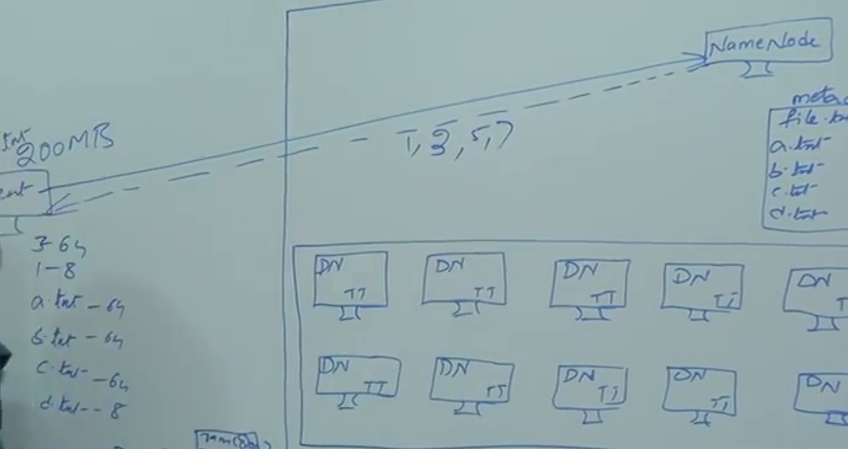
Client communicate with Name Note
Name not will give responds to client which location data needs to be stored
For example if 1,3,5,7 then a.txt will be stored under Data node 1

What will happened if Node 1 is going to down where a.txt saved. To make the availability by default it gives 3 replication by default, a.txt file will be copied into another 2 notes, for example Node2 and Node4.
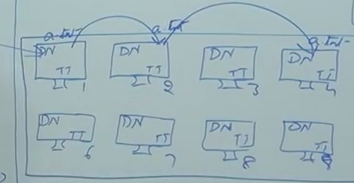
Acknowledgement will be given after each saved on noted (dot dot line)
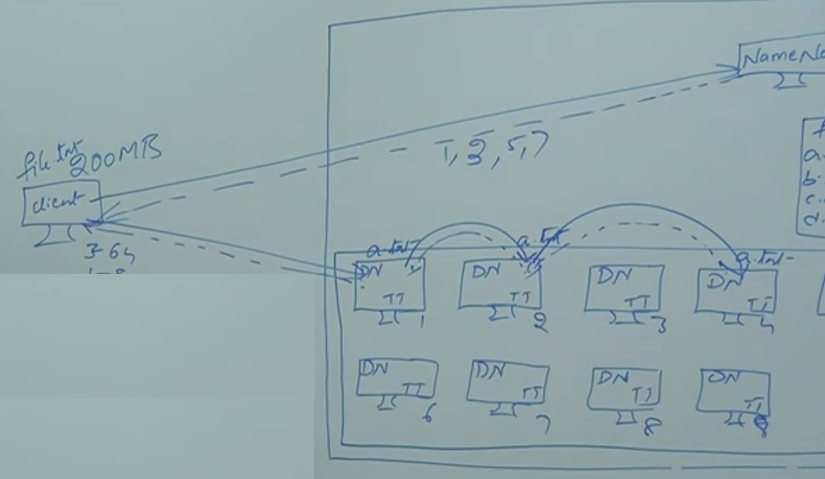
How this name notes know which notes this a.txt file saved
All the slave notes give proper blog reports to Name node every sort period of time, to say that some client store data on it and still alive and processing properly (heart beat)
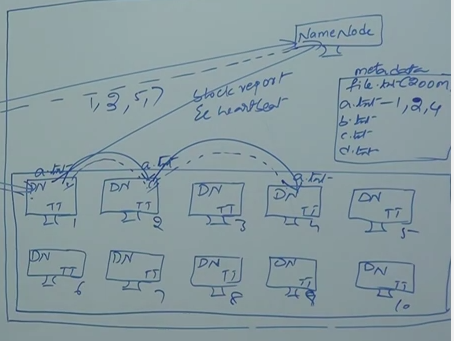
Blog report will update on Name node

Some other important points are:
200 MB file will be store in 600MB space because of REPLICATION
Based on slave notes heard beat Name note will update the meta data. For example if note 2 is down then it remote note 2 for a.txt, and name note will choose another not to store a.txt
When note come back alive, but that data note don’t have any more data, it will start as fresh.
Map reduce:

Let say you have written a 10 KB program, you need to bring 200MB data to client so send the 10KB program to HDFS. Here on ward job tracker will handle.
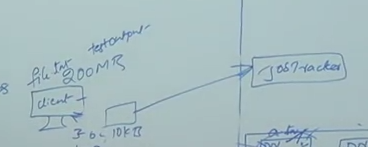
No communication between job tracker and data notes

Job tracker assign task to Task tracker
Task tracker will be chosen based on nearest one.
For example 10 KB program will be assign/send to task tracker 1 in node1- This process called map

200MB file = a.txt, b.txt, c.txt and d.txt
Job taker send 10 KB program to node1 for a.txt, note3 for b.txt , note 5 for c.txt and node 7 for d.txt. THIS IS CALLED MAP
Input file = 200 MB (this will split into a, b,c and d)
Input splits = a.txt, b.txt, c.txt and d.txt

No of file splits = no of map process
Any case any of the task tracker not able to process, then job tracker will assign to another task tracker
All these task trackers are slave service for job tracker, so task trackers gives heard beat back to job tracker every 3 minutes.
If particular task tracker is busier, job tracker will decide to change the task tracker
Job tracker can monitor all the task trackers
If job tracker down all the process data will be lost for that Name node and Job tracker node we use high reliable hardware.
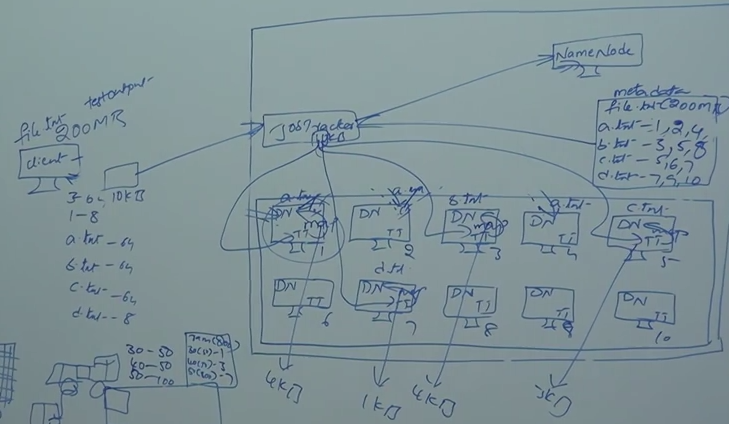
Task tracker find the information about this files and output will be store, for example output files 4KB,1 KB,4KB,3KB. One the information find each and every Name node separately, the output file will be used by reducer.
Reducer can be any node, if node 8 process reduce then it will put the final output in node 8 and update to node 8.
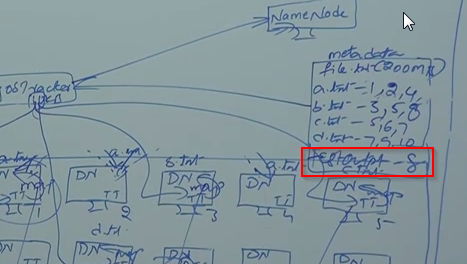

Instead of copy whole data and process, program is sent each node and find the output separately and finally combine the output.
Cheers!
Uma
Uma