This blog is about Create Partitioned Tables via T-SQL script and SQL Server Management Studio. Partitioning can make large tables and indexed more manageable and scalable. The data in partition tables and indexed is horizontally divided into units that can be spread across more than one file group in a database. SQL Server 2012 supports up to 15,000 partitions by default. In earlier versions, the number of partitions was limited to 1,000 by default. On x86-based systems, creating a table or index with more than 1000 partitions is possible, but is not supported.
Once you create a new database, you can see there is default file group called PRIMARY as shown below.

The following steps are needed to follow to create a partition via SQL Server Management Studio.
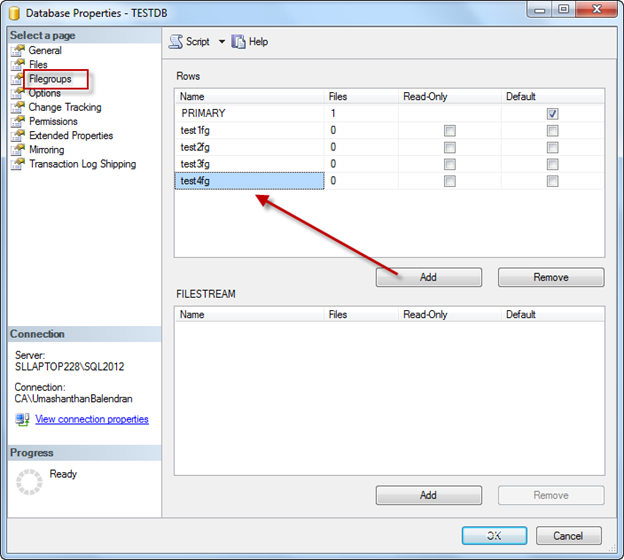
Step 1: Add 4 more file group
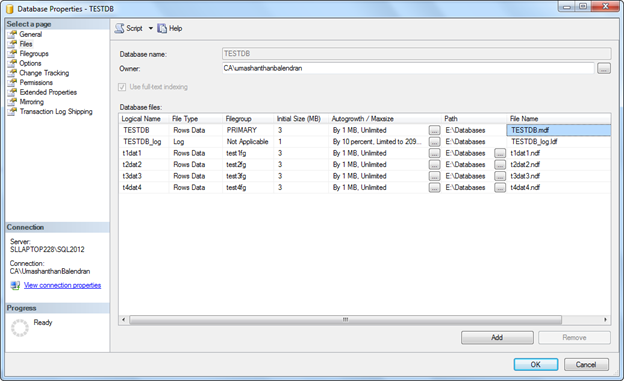
Step 2: Add 4 files and assign to each file group.
Step 3: To create partition use Create partition wizard, by right click on particular table
Step 4: Select the column in a table to apply for partition.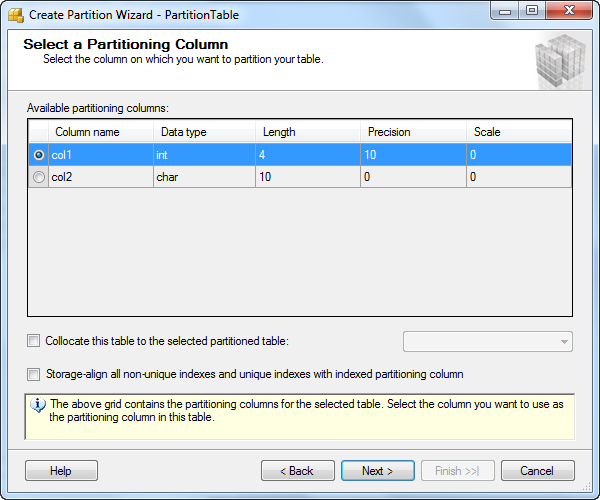
Step 5: Type the Partition Function name
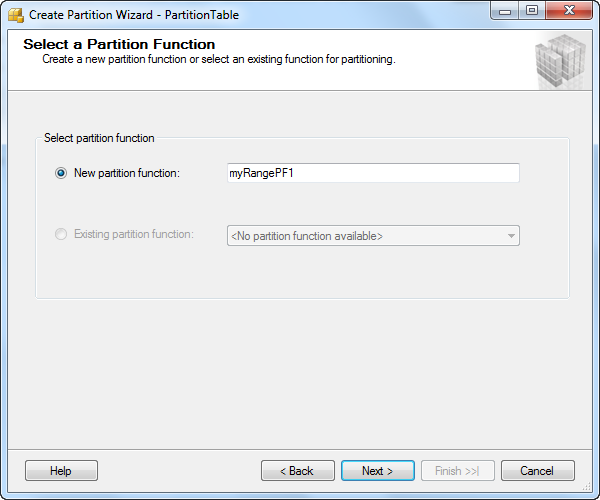
Step 6: Type Partition Scheme name

Step 7: Define the boundary for each file group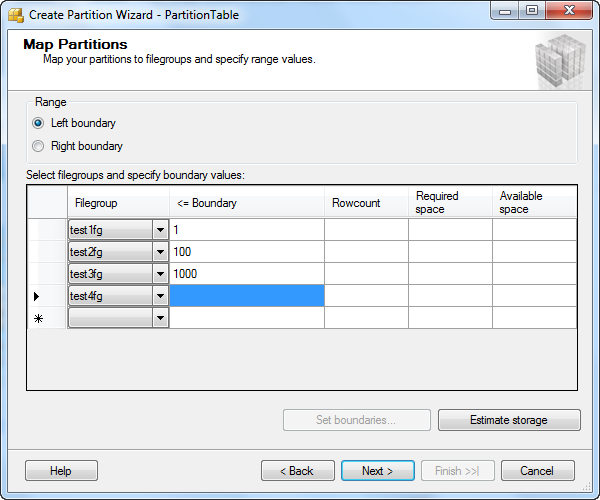
Step 8: You can create the script for these and run it alter or run immediately.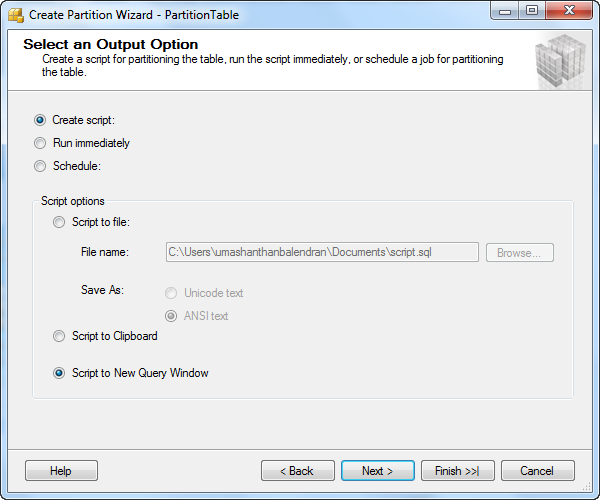
Step 9: insert some values and check whether values are inserting into appropriate file group.

In the same way the following steps have to follow for create partition using T-SQL script.
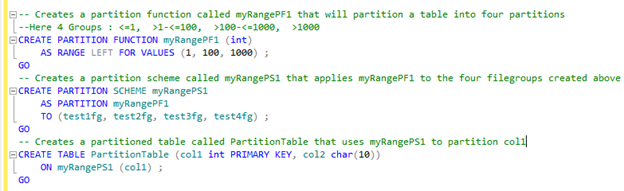
Create 4 new measure group called test1fg, test2fg, test3fg and test4fg.

Once you run this script you will see there will be 4 more measure group will be available in the database. After that create file group, you have to a create file and add to each file group, for the best practice each file in a different drive would increase the performance.

You need to create Partition Function, Partition Scheme and then assign this partition function to the relevant table. In here I have created Partition Function called myRangePF1 using integer value with 3 parameters; in this case there will be 4 ranges
1. <=1
2. >1 and <=100
3. >100 and <=1000
4. >100
On the Map Partitions page, under Range, select either Left boundary or Right boundary to specify whether to include the highest or lowest bounding value within each filegroup you create. You must always enter one extra filegroup in addition to the number of filegroups specified for the boundary values when you are creating partitions.
In here I created sample table called Partition Table with two column one is integer and another one character field and then assign integer column into Partition Function. The below screen shot will make you clear.
When I insert -1, you will be see that it will insert into test1fg file group as shwon below.
Cheers!