In this post I write about some of the most important ways to optimize the performance of SSIS. Most of these ideas I got t from one of the training via internet.
Buffer Sizing

What are these DefaultBufferMaxRows and DefaultBufferSize?
The default value is 10MB (10485760 B) and its upper and lower boundaries are constrained by two internal non configurable properties of SSIS which are MaxBufferSize (100MB) and MinBufferSize (64KB). It means the size of a buffer can be as small as 64KB and as large as 100MB.


Although SSIS engine does a good job in tuning for these properties in order to create an optimum number of buffers, if the size exceeds the DefaultBufferSize then it reduces the row in the buffer. For the better performance follow one of these.
- You can remove unwanted columns and set the data type in each column appropriately.
In source extract you can use query conversion to reduce the data length if possible.
Also you can find the unused column form warning messages.

Data type can be find appropriately, by data profiling such as if a column has max character length is 50, then define Varchar(50).
- Based on the system memory, you can tune these properties to have small number of large buffer, which could improve your performance.
You can get the idea about the buffer size tuning, using Log package with BufferSizeTuning to see adjustment of buffers.
Enable the Log Event Window, before running package; this will help to get the log event description, without got to the log file or other source.
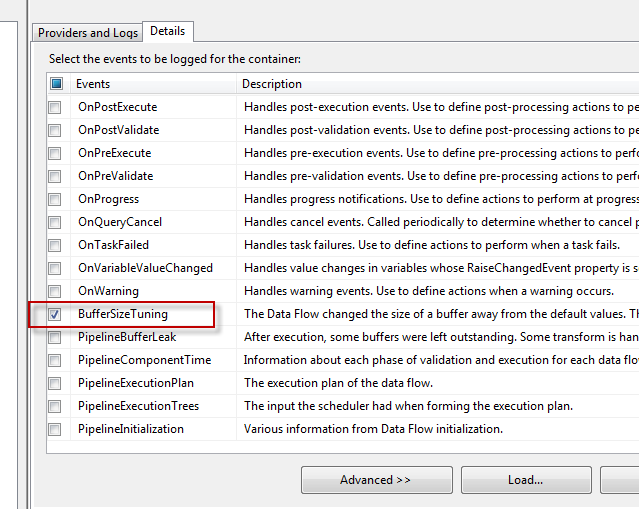
To read the Log file, enable Log Events windows as shown below.

Once you run the package and stop, you will see the details of log in Log Event Window:
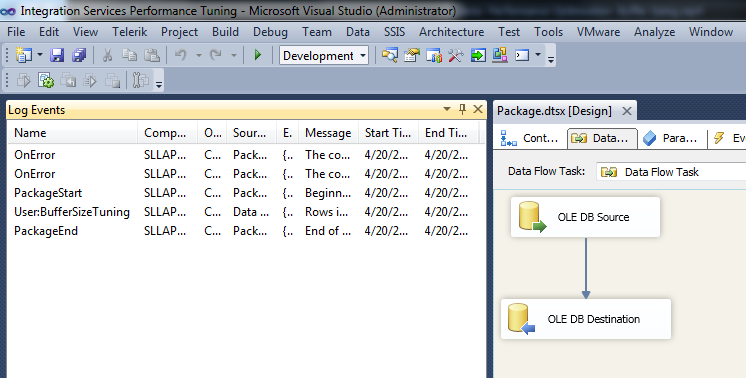

This log detail gives information to tune the buffer size or Max number of Rows.
Parallelism
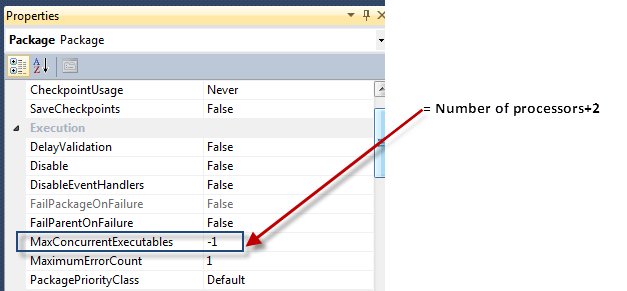
Increase the MaxConcurrentExecutables on dedicated server: By default it is set to -1, in this case number of concurrent executables = number of processors + 2.
This can be changes based on the server hardware configuration.
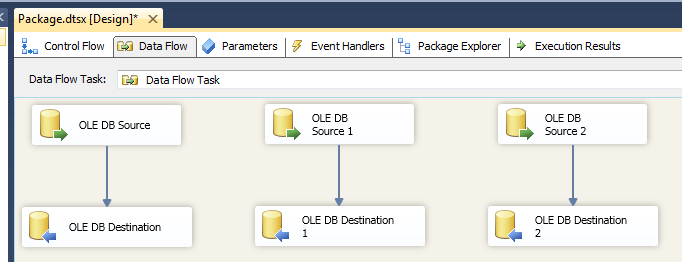
Use parallel pipelined in data flow with separate data sets
Transformations:
Choose transformation carefully, use Non-blocking data flow task, as much as possible.

Reduce rows with conditional split where possible.

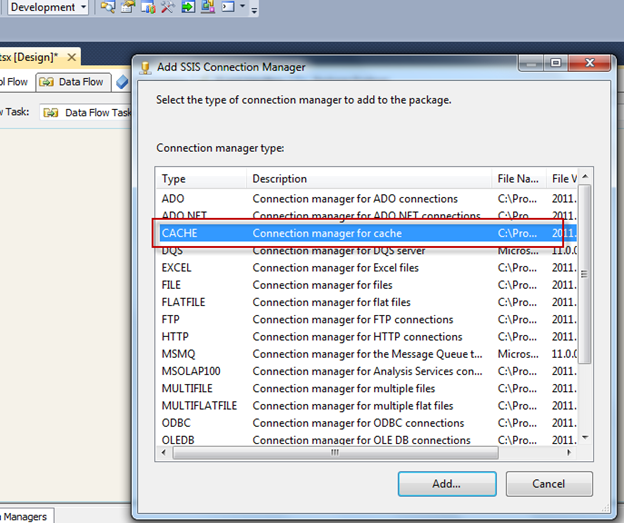
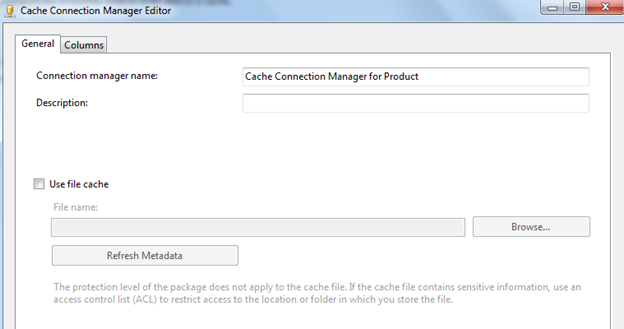
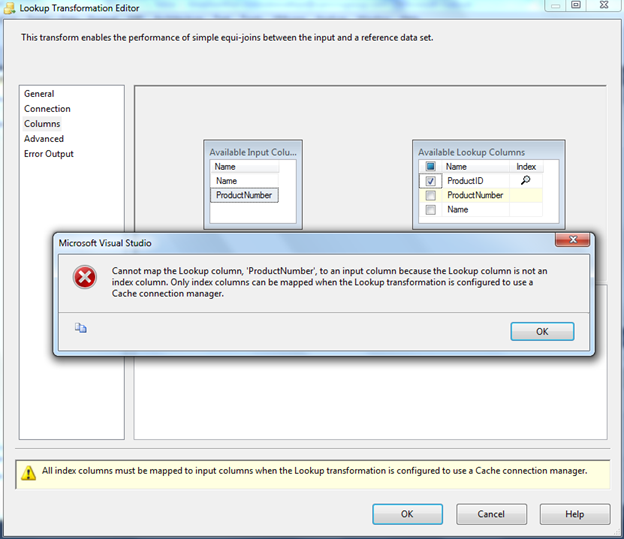
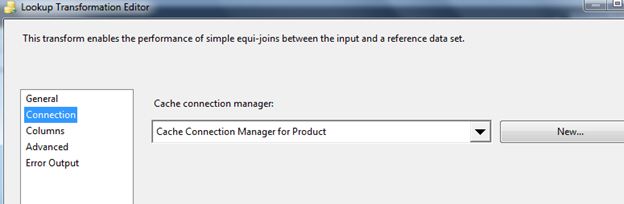
Optimize the Lookup cache

Source Data:
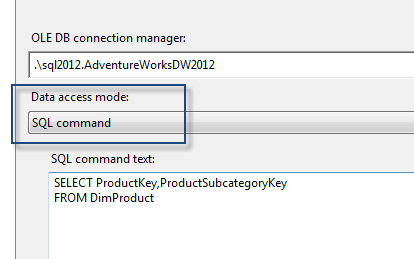
You have to take data which you required only. Rather than select all the column in the source table use SQL Command, for that try to use Data Access Mode: SQL Command for relational source
Make it FastParse option for flat file source

OLE DB Destination:
Use fast load option, this will do the Bulk Insert instead of insert row by row.
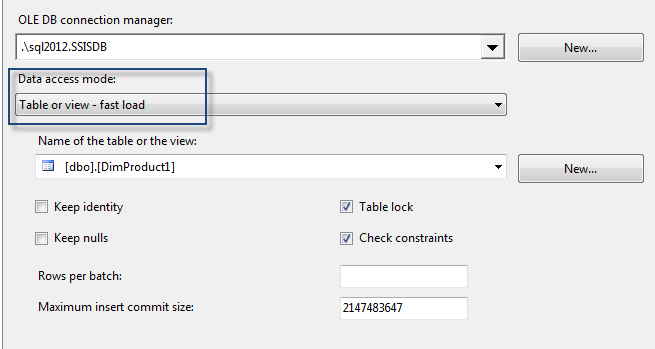
- Also Table Lock makes the faster performance.
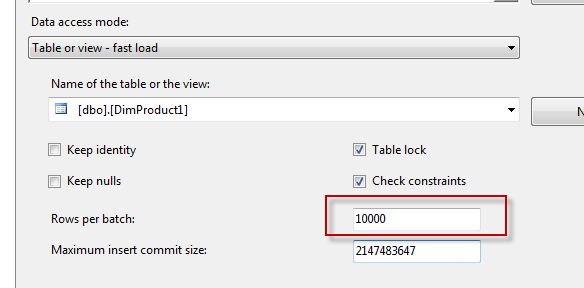
If we set Rows per Batch, when we dealing with Clustered Index, integration have short the rown before insert, that can take some time. If define the Rows Per Batch, we can limit the number of shorting and increase the performance of insert. If not we can drop the index before start insert and load rows asd rebuild the Index.
Other than this Memory, CPU and Network configuration also can increase the performance. Mainly make sure the Buffer spooled always be in 0, if not indication for that memory is not sufficient to hold the data.