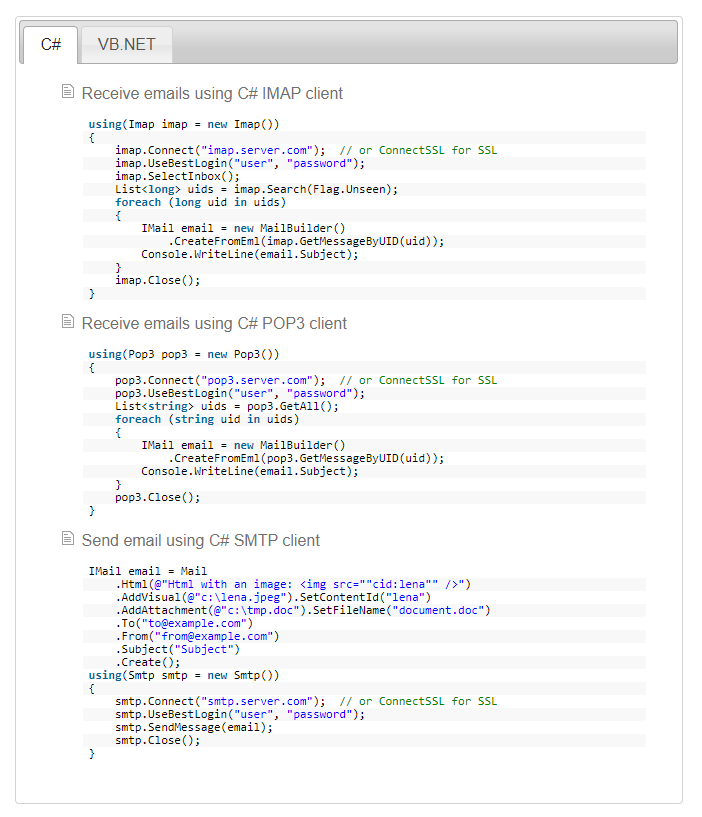
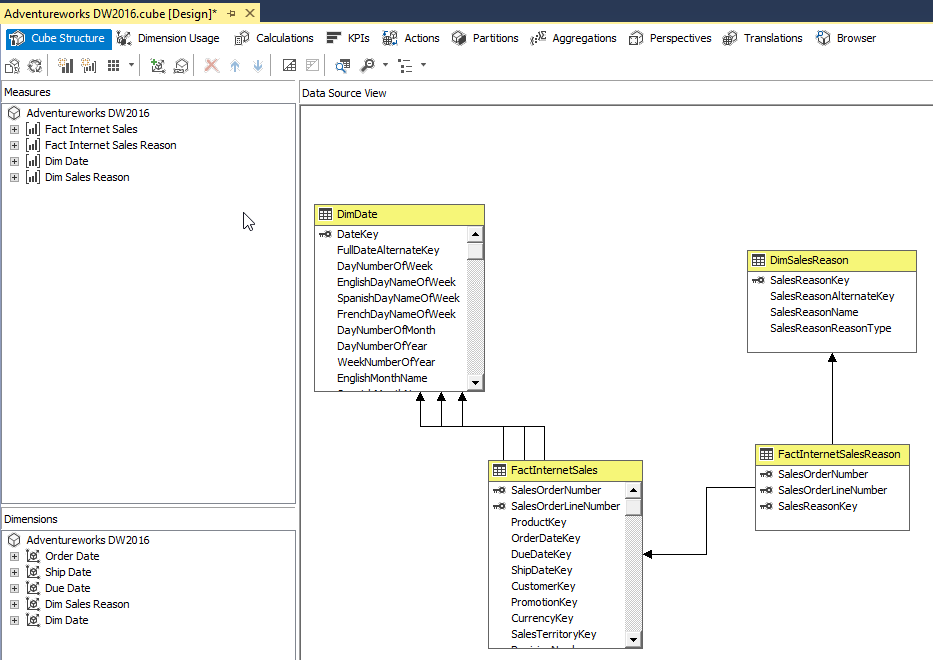
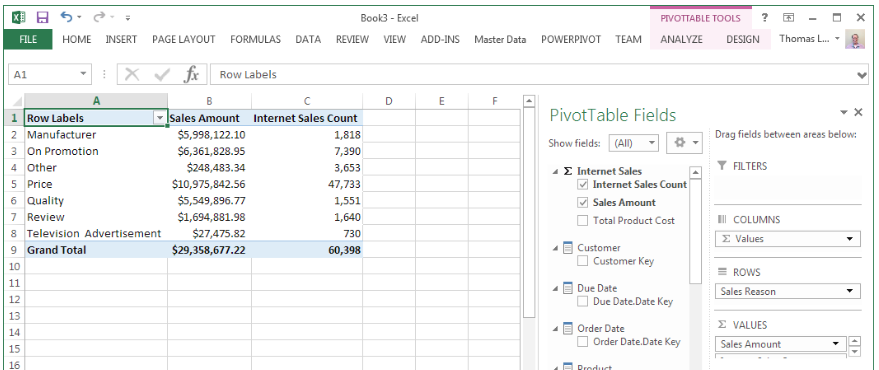
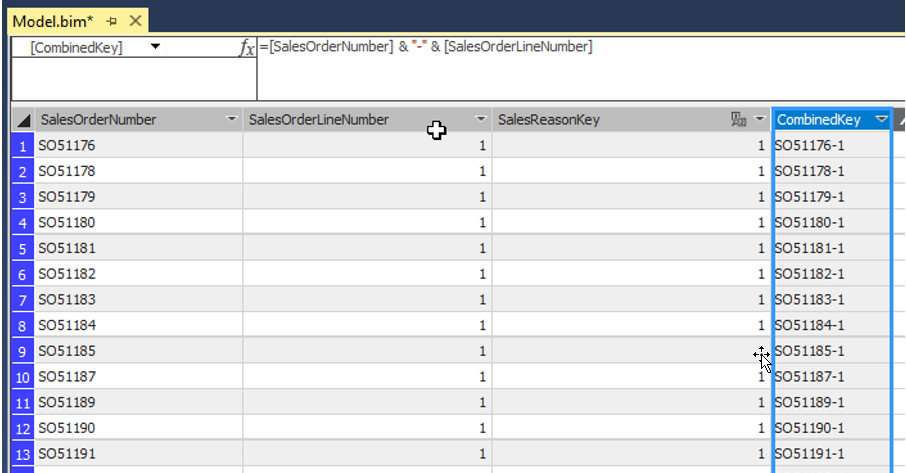
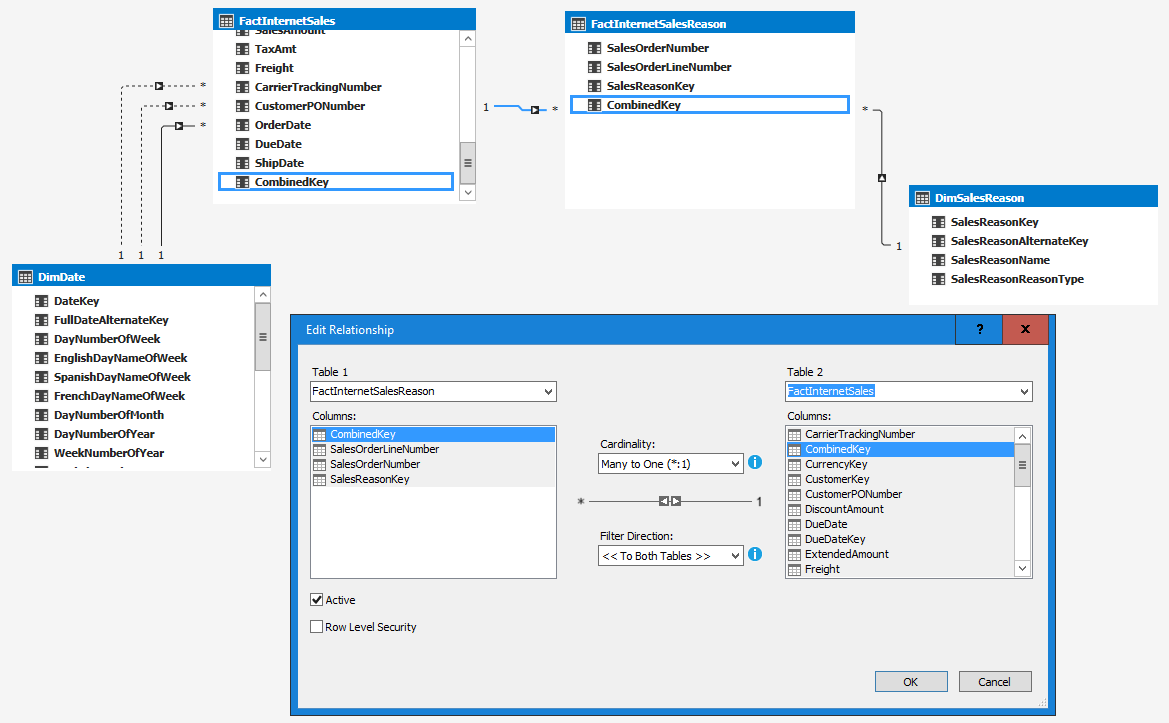
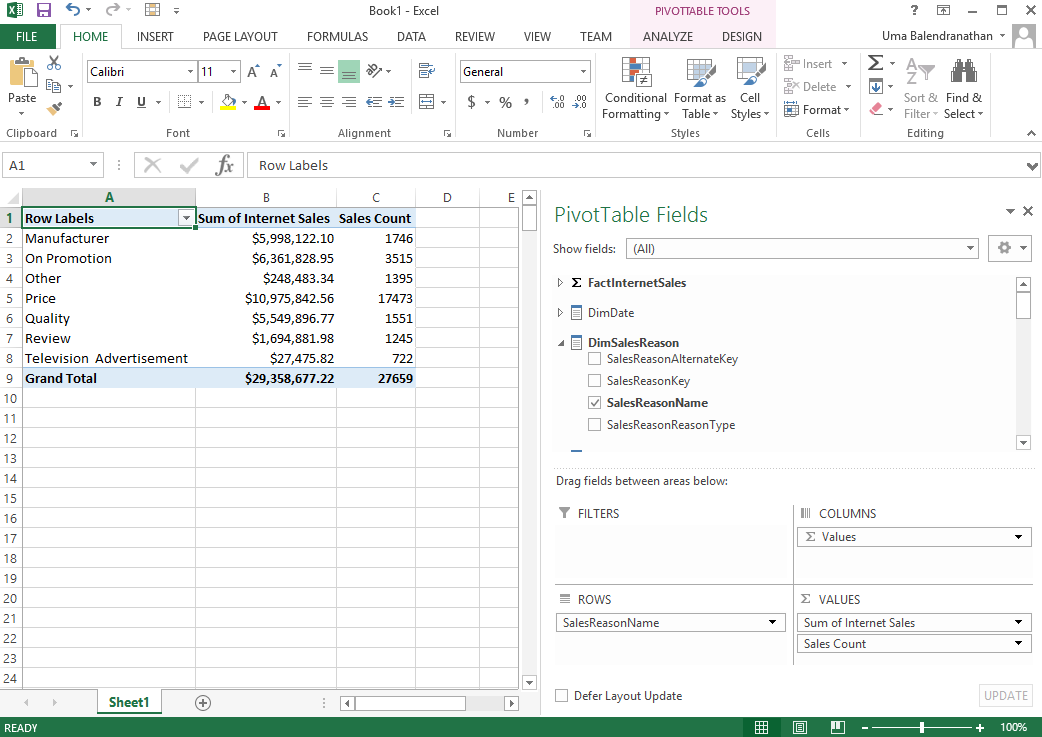
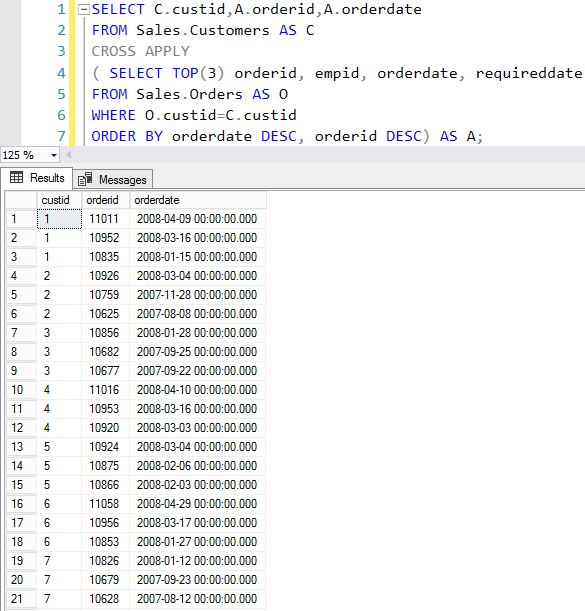
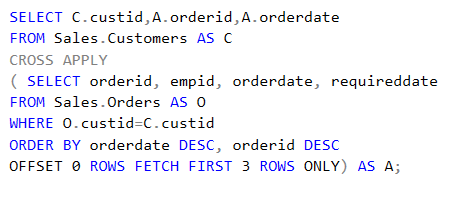
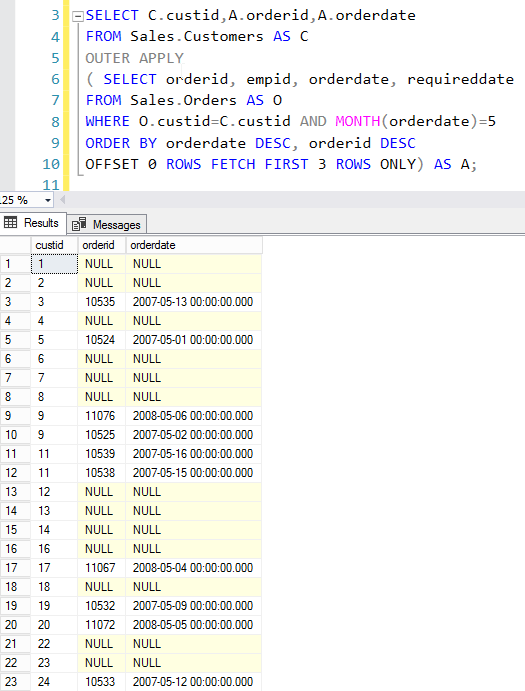
SQL Server provides two features that track changes to data in a database: change data capture and change tracking. These features enable applications to determine the DML changes (insert, update, and delete operations) that were made to user tables in a database.
Change Data Capture
Change data capture provides historical change information for a user table by capturing both the fact that DML changes were made and the actual data that was changed. Changes are captured by using an asynchronous process that reads the transaction log and has a low impact on the system.
Change Tracking
Change tracking captures the fact that rows in a table were changed, but does not capture the data that was changed. This enables applications to determine the rows that have changed with the latest row data being obtained directly from the user tables. Therefore, change tracking is more limited in the historical questions it can answer compared to change data capture. However, for those applications that do not require the historical information, there is far less storage overhead because of the changed data not being captured. A synchronous tracking mechanism is used to track the changes. This has been designed to have minimal overhead to the DML operations.
The main feature differences is Change Data Capture keep historical data and Change tracking only keep latest change using version control.
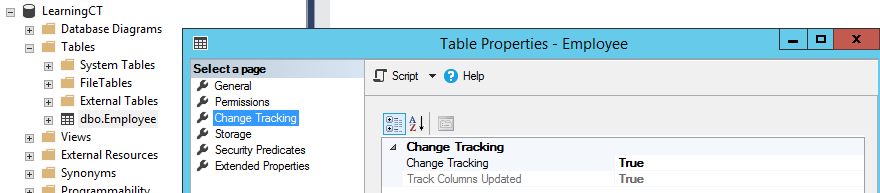
To enable Change Tracking for Database:
ALTER DATABASE LearningCT
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON)
To enable Change Tracking for Table:
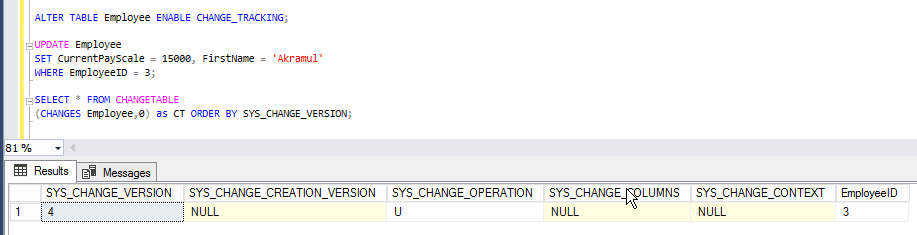
ALTER TABLE Employee
ENABLE CHANGE_TRACKING;
or
ALTER TABLE Employee
ENABLE CHANGE_TRACKING
WITH (TRACK_COLUMNS_UPDATED = ON);
One of the main condition before enable Change Tracking, the table should have primary key otherwise you will get the following error.
Cannot enable change tracking on table 'Employee1'. Change tracking requires a primary key on the table. Create a primary key on the table before enabling change tracking
The only parameter is TRACK_COLUMNS_UPDATED. When set to OFF, only the fact that the row has been changed is stored. When set to ON, the information which columns were updated is also stored, which can be read using the HANGE_TRACKING_IS_COLUMN_IN_MASK function, as shown in Part II. As this option adds overhead, it is set to OFF by default.
You can see the difference with and without these options
You can join this change tracking table with original table to find the change data.
SELECT Employee.*
FROM Employee
LEFT JOIN CHANGETABLE(CHANGES Employee, @latest_version) AS CHANGES
ON Employee EmployeeID = CHANGES.EmployeeID
WHERE (CHANGES.SYS_CHANGE_OPERATION IN ('I', 'U')
In here, @latest_version can be derived via:
SELECT CHANGE_TRACKING_CURRENT_VERSION ()
Please refer the following links for more details
Cheers!
Uma