Hadoop cluster in one of the three supported modes
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Fully-Distributed Mode
Standalone Operation / Single node setup
By default, Hadoop is configured to run in a non-distributed mode, as a single Java process.
The following example copies the unpacked conf directory to use as input and then finds and displays every match of the given regular expression. Output is written to the given output directory.
$ mkdir input
$ cp etc/hadoop/*.xml input
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'
$ cat output/*
Pseudo-Distributed Operation
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
For example, HDFS configuration define separate nodes for NameNode and DataNode, but in same machine.
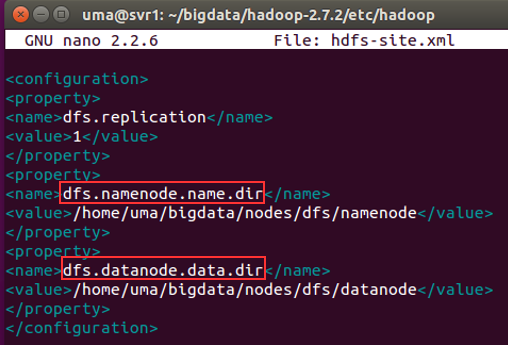
If you start HDFS and Yarn, using jps command you can check how many separate daemons running in Hadoop. Note that all the daemons are running on same machine.

Installing a Hadoop cluster typically involves unpacking the software on all the machines in the cluster or installing it via a packaging system as appropriate for your operating system. It is important to divide up the hardware into functions.
Typically one machine in the cluster is designated as the NameNode and another machine the as ResourceManager, exclusively. These are the masters. Other services (such as Web App Proxy Server and MapReduce Job History server) are usually run either on dedicated hardware or on shared infrastrucutre, depending upon the load. The rest of the machines in the cluster act as both DataNode and NodeManager.
After reading this blog i very strong in this topics and this blog really helpful to all Big data hadoop online Training
ReplyDeleteStorage: The integrated data is stored in a way that optimizes it for read access and complex queries. This means that data warehouses are typically organized using schemas such as star schemas or snowflake schemas, which facilitate efficient querying and reporting.
DeleteBig Data Projects For Final Year
Analysis: Unlike operational databases, which are designed for transaction processing and real-time operations, data warehouses are designed for complex queries and analysis. This includes generating reports, performing trend analyses, and running data mining operations.
Nice and good article. It is very useful for me to learn and understand easily. Thanks for sharing your valuable information and time. Please keep updating Hadoop Admin online training
ReplyDelete